Pythona zacząłem używać jakieś 5 lat temu. Na początku nie byłem przekonany, ale nie miałem wyboru. Z czasem się przekonałem i zrobiłem kilka projektów małych i dużych. Dodatkowo uczyłem podstaw programowania w pythonie przez 4 lata – do tej pory nie jestem przekonany czy jest to dobry język na początek (trochę za dużo wybacza), ale nie była to moja decyzja.
Wracając do tematu: python ma jedną poważną wadę – jest strasznie wolny. Dziś chcę wam pokazać na przykładzie, jak w prosty sposób można użyć funkcji napisanych w C/C++ do przeprowadzania obliczeń w programie w napisanym w pythonie. Python jest rewelacyjny jeśli chodzi o wczytywanie, zapisywanie i wizualizację danych, z kolei C/C++ jest bardzo wydajny. Połączenie wydaję się idealne i okazuje się całkiem proste.
Dla przykładu weźmy proste zadanie: generujemy listę N liczb losowych z zakresu od 0 do 1. Chcemy obliczyć wszystkie możliwe sumy 3 liczb z tej listy bez powtórzeń i policzyć ile z nich wynosi 1 z pewną ustaloną dokładnością. Oczywiście można ten problem optymalizować, ale dziś nie o tym. Chcemy porównać wydajność czystego pythona i pythona wspieranego przez C++.
W pierwszej kolejności napiszmy sobie funkcję w C++ (plik CALC.cpp):
#include "CALC.h"
#include
#include
#include
void _CALC(double *DATA, int *RESULT, int N, double treshold)
{
printf("C++ start\n");
RESULT[0] = 0;
for (int a = 0; a < N; a++)
{
for (int b = a+1; b < N; b++)
{
for (int c = b+1; c < N; c++)
{
if (fabs(DATA[a] + DATA[b] + DATA[c] - 1) < treshold)
{
RESULT[0]++;
}
}
}
}
printf("C++ finish\n");
}
W parze mamy plik nagłówkowy (CALC.h):
void _CALC(double *DATA, int *RESULT, int N, double treshold);
Powyższa funkcja robi dokładnie to co założyliśmy - zlicza ile kombinacji bez powtórzeń daje sumę 1 z dokładnością "treshold". Za chwilę powinno być jasne, czym są argumenty tej funkcji.
Naszym celem jest możliwość wywołania tej funkcji z poziomu pythona w taki sposób (program.py):
import numpy
import CALC
import time
start_time = time.time()
N = 1000
treshold = 1e-7
DATA = numpy.random.uniform(0, 1, size=N)
RESULT = numpy.zeros((1,), dtype=numpy.int)
start_time = time.time()
CALC.CALC(DATA, RESULT, N, treshold)
t1 = (time.time() - start_time)
print("C++:", RESULT[0], t1)
start_time = time.time()
count = 0;
for a in range(0,N):
for b in range(a+1,N):
for c in range(b+1,N):
if abs(DATA[a]+DATA[b]+DATA[c]-1) < treshold:
count =count + 1
t2 = (time.time() - start_time)
print("Python:", count, t2)
print("Speed:", t2/t1)
Dokładnie chodzi o linię
CALC.CALC(DATA, RESULT, N, treshold)
Potrzebujemy powiązania (interfejsu) pomiędzy pythonem i C++ (CALCmodule.cpp). Jest to kawałek kody, który z naszej funkcji C++ pozwala zrobić moduł dla pythona. Nie pisałem tego sam, złożyłem z kilku tutoriali. Najważniejsza jest funkcja CALC, gdzie definiujemy nasze zmienne i wywołujemy funkcję liczącą:
#include
#define NPY_NO_DEPRECATED_API NPY_1_10_API_VERSION
#include
#include "CALC.h"
struct module_state {
PyObject *error;
};
#define GETSTATE(m) ((struct module_state*)PyModule_GetState(m))
static PyObject* CALC(PyObject* self, PyObject* args)
{
PyArrayObject *data_obj;
PyArrayObject *result_obj;
double treshold;
int N;
if (!PyArg_ParseTuple(args, "OOid", &data_obj, &result_obj, &N, &treshold))
{
Py_INCREF(Py_None);
return Py_None;
}
double *DATA = static_cast(PyArray_DATA(data_obj));
int *RESULT = static_cast(PyArray_DATA(result_obj));
_CALC(DATA, RESULT, N, treshold);
Py_INCREF(Py_None);
return Py_None;
}
static PyMethodDef CALCMethods[] = {
{"CALC", CALC, METH_VARARGS, "..."},
{NULL, NULL, 0, NULL}
};
static int CALC_traverse(PyObject *m, visitproc visit, void *arg) {
Py_VISIT(GETSTATE(m)->error);
return 0;
}
static int CALC_clear(PyObject *m) {
Py_CLEAR(GETSTATE(m)->error);
return 0;
}
static struct PyModuleDef moduledef = {
PyModuleDef_HEAD_INIT,
"CALC",
NULL,
sizeof(struct module_state),
CALCMethods,
NULL,
CALC_traverse,
CALC_clear,
NULL
};
extern "C" PyObject * PyInit_CALC(void)
{
PyObject *module = PyModule_Create(&moduledef);
if (module == NULL)
return NULL;
struct module_state *st = GETSTATE(module);
st->error = PyErr_NewException("CALC.Error", NULL, NULL);
if (st->error == NULL)
{
Py_DECREF(module);
return NULL;
}
import_array();
Py_INCREF(module);
return module;
}
Na stronie https://docs.python.org/2/c-api/arg.html znajdują się dokładnie opisy typów danych które możemy przekazywać z pythona do C++ i z powrotem. W powyższym przykładzie "OOid" oznacza dwa obiekty, liczbę całkowitą i zmiennoprzecinkową (double). Obiektem może być lista, z której możemy czytać i do której pisać. Nazwa naszego modułu pojawia się w tym kodzie wielokrotnie - zmieniając trzeba pamiętać o wszystkich miejscach.
Ostatnim krokiem jest kompilacja modułu. Potrzebujemy skryptu do kompilacji (setup.py):
from distutils.core import setup, Extension
import numpy.distutils.misc_util
import os
os.environ["CC"] = "g++"
os.environ["CXX"] = "g++"
module1 = Extension('CALC', sources = ['CALCmodule.cpp', 'CALC.cpp'])
setup (name = 'CALC',
version = '1.0',
description = 'Package for calculating number sums',
ext_modules = [module1],
include_dirs=numpy.distutils.misc_util.get_numpy_include_dirs())
Teraz możemy kompilować i uruchamiać:
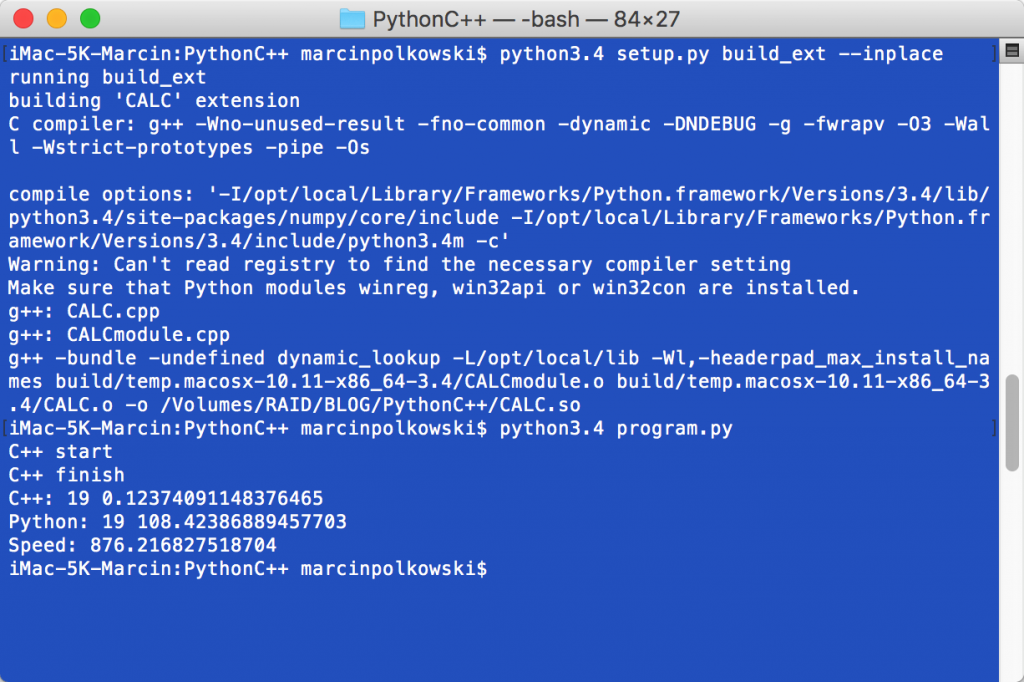
Funkcja w C++ potrzebowała 0.12 sekundy na policzenie, że jest 19 trójek, które z dokładnością 0.0000001 dają sumę 1. Python potrzebował na analogiczne liczenie 108.42 sekund: 876 razy dłużej! Oczywiście można by ten kod zoptymalizować, ale porównujemy dwa identyczne rozwiązania. Różnica w czasie jest kolosalna. W mojej pracy często spotykam się z obliczeniami numerycznymi, dlatego w pierwszej kolejności przygotowuję prototyp w pythonie i fragment obliczeniowy przepisuję na C++.
Nie chcę wnikać w teorię budowania modułów dla pythona bo się na tym nie znam. Sam najlepiej uczę się na przykładach, więc mam nadzieję, że ten Wam się przyda.
Dajcie znać, czy kiedyś używaliście takich rozwiązań, albo czy przydadzą Wam się w przyszłości.